
I’m a PhD candidate at KTH specializing in multimodal machine learning for embodied communication. I build generative models and multimodal datasets that enable robots and avatars to interact naturally with people.
Anna Deichler
deichler.anna@gmail.com
Deichler, A., O'Regan, J., Dogan, F. I., Marcinek, L., Klezovich, A., Leite, I., & Beskow, J. • LREC 2026 (Language Resources and Evaluation Conference)
• Introduced a multimodal dataset and benchmark for context-aware grounding in situated 3D dialogue.
• Developed a linguistic taxonomy covering referential expressions (full NPs, partitives, pronominals, implicit references).
• Includes 4,200 manually verified expressions with human evaluation and benchmarking of LLM/VLM models on grounded dialogue tasks.
Deichler, A., and Beskow, J.
•
SpaVLE Workshop @ NeurIPS 2025
 arXiv:2510.22672
arXiv:2510.22672
• Multimodal referential-communication dataset linking language, gaze, and video across ego & exo views.
• Enables benchmarking of spatial representations for grounded dialogue in embodied agents.
• Dataset page (Hugging Face)

Deichler, A., O’Regan, J., Guichoux, T., Johansson, D. and Beskow, J.•
Humanoid Agents Workshop @ CVPR 2025
•
Poster
arXiv:2507.04522
• Benchmark and framework for grounded gesture generation combining language, motion, and 3D scene context.
• Over 7.7 hours of synchronized motion, speech, and scene data in HumanML3D format.
• Spatially conditioned fine-tuning (OmniControl) produces natural pointing gestures.
• Project page
Deichler, A., O’Regan, J., and Beskow, J.•
Multi-Modal Agents Workshop @ ECCV 2024
•
Oral
arXiv:2410.00253
• Collected a novel multi-modal conversational dataset (MM-Conv) recorded in VR in referential communication settings.
• Includes egocentric video and motion capture data for context-aware behavior generation in virtual avatars.
• Project website
Mehta, S., Deichler, A., O’Regan, J., Moell, B., Henter, G.E., Beskow, J., and Alexanderson, S.•
HuMoGen Workshop @ CVPR 2024
•
Poster
•
Best Paper Award
arXiv:2410.00253
• Demonstrated that pre-training on unimodal synthetic data significantly improves the quality of joint speech and gesture generation.
• Won Best Paper Award at the workshop.
Deichler, A., Alexanderson, S., and Beskow, J.• ACM IVA 2024
arXiv:2408.04127
• Introduced a synthetic dataset for a novel data-driven spatial gesture generation task.
• Presented a framework for incorporating spatial reasoning in gesture generation.
Werner, A., Beskow, J., and Deichler, A.•Genea Workshop, ACM ICMI 2024
arXiv:2509.12816
• Supervised master thesis project at KTH EECS.
• Compared VR-based gesture evaluation to traditional 2D methods.
• Results highlight VR's potential for more immersive and accurate gesture evaluation.
Deichler, A., Mehta, S., Alexanderson, S., and Beskow, J.• ACM ICMI 2023
arXiv:2509.12816
• Developed a semantic co-speech gesture generation system based on diffusion models and contrastive pre-training..
• Rated highest in naturalness and speech appropriateness in a large-scale gesture evaluation (GENEA).
• Interactive Demo Page
Deichler, A., Wang, S., Alexanderson, S., and Beskow, J.• Frontiers in Robotics and AI, 2023
arXiv:2509.12507
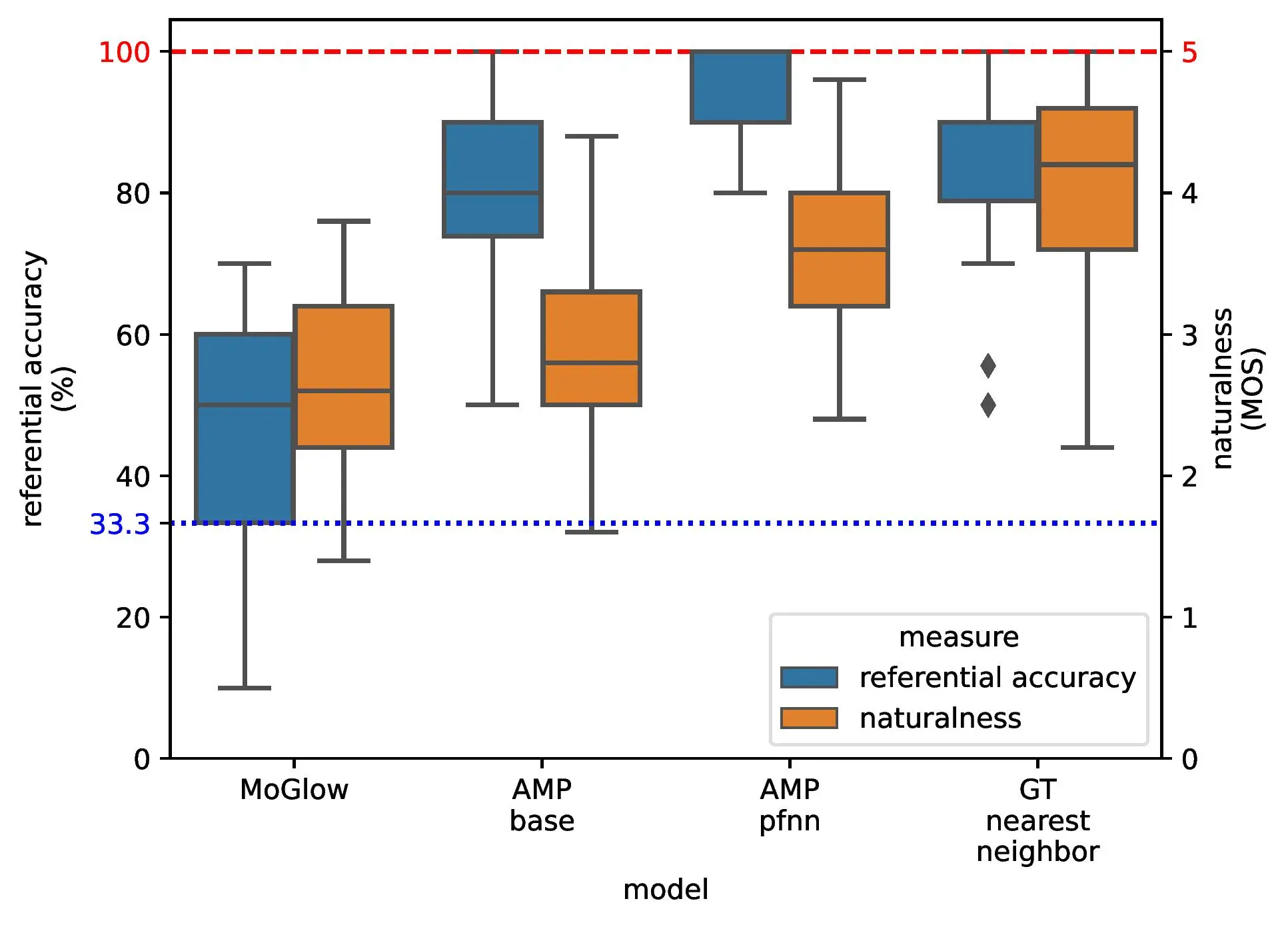
• Developed an RL-imitation-based algorithm (AMP-base, AMP-pfnn) that produces accurate and human-like pointing gestures.
• Integrated into a novel VR-based framework for gesture evaluation.
Torre, I., Deichler, A., Nicholson, M., McDonnell, R., and Harte, N.• IEEE RO-MAN 2022
• Explored the impact of mismatched emotional expressions in human-robot teamwork scenarios.
Deichler, A*., Wang, S.*, Alexanderson, S., and Beskow, J.• HRI Workshop 2022
arXiv:2509.12880
• Presented a framework for generating context-aware pointing gestures using RL motion imitation.
• Demonstrated advancements in human-like pointing gestures in human-robot interaction.
Deichler A*, Chhatre K*, Beskow J, Peters C• IEEE ICDL - StEPP 2021
• 1st Workshop on Spatio-temporal Aspects of Embodied Predictive Processing (StEPP)
• paper link
Jonell P*, Deichler A*, Torre I, Leite I, Beskow J• IEEE RO-MAN - SCRITA 2021
• 4th Workshop on Trust, Acceptance and Social Cues in Human-Robot Interaction (SCRITA)
Moerland TM*, Deichler A*, Baldi S, Broekens J, Jonker C• ICAPS - PRL 2020
arXiv:2005.07404
• 1st workshop on Bridging the Gap Between AI Planning and Reinforcement Learning (PRL)
• paper link
Werner, A. • MSc Thesis, KTH EECS • 2024
Shenawa, A. • MSc Thesis, KTH EECS • 2024
Qian, S. • MSc Thesis, KTH EECS • 2024
PhD in Computer Science •Stockholm• 2021-
• main topic: machine learning for nonverbal behaviour adaptation in robotics
• supervisors: Jonas Beskow, Iolanda Leite
MSc in Systems and Control •Delft• 2019
• robotics profile
• core modules in control theory, optimization, nonlinear system theory, electives in deep learning, computer vision, artificial intelligence
• thesis project: Generalization and locality in the AlphaZero algorithm (thesis supervisors: Thomas Moerland, Simone Baldi)
• Access thesis
• Planning • Monte Carlo tree search • Deep learning • Python• Tensorflow
Generalization and locality in the AlphaZero algorithm
The AlphaGo was first to achieve professional human level performance in the game of Go. It combined pattern knowledge through the use of a deep neural network and search using Monte Carlo tree search (MCTS).
MCTS uses local and dynamic position evaluation in contrast to traditional search methods, where static evaluation functions store knowledge about all positions.
It has been suggested that the locality of information is the main strength of the MCTS algorithm. As each edge stores its own statistics, it is easier to locally separate the effect of actions.
On the other hand, the main strength of deep neural networks is their generalization capacity, which allows them to utilize information from previous experience to new situations.
It can be argued that the success of AlphaGo can be explained by the complementary strengths of MCTS and deep neural networks.
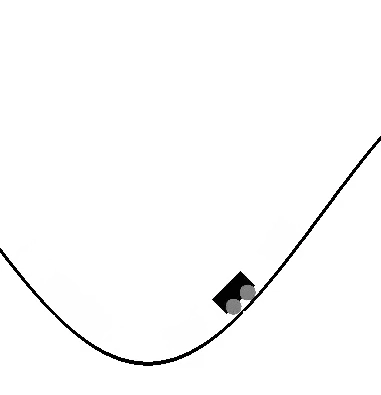
The thesis examines the relative importance of local search and generalization in the AlphaZero algorithm in single-player, deterministic and fully-observable reinforcement learning environments (OpenAI, Pybullet gym environments).
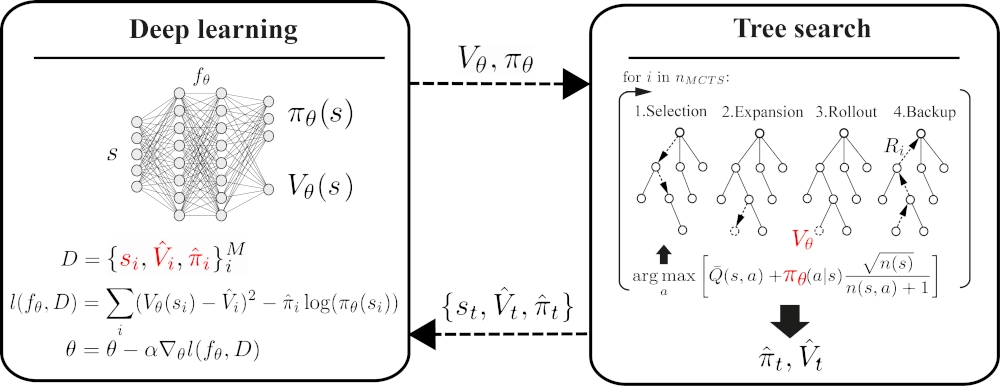
The localization versus generalization question was examined through varying the number of MCTS iteration steps N_MCTS, while keeping other hyperparameters of the algorithm fixed.
The N_MCTS parameter corresponds to the number of simulated trajectories performed using the environment emulator before each action selection step in the real environment.
Under a fixed time budget the number of MCTS iterations defines how much effort is spent on acquiring more accurate values through building large search trees at each decision step versus improving generalization by updating the network more frequently.
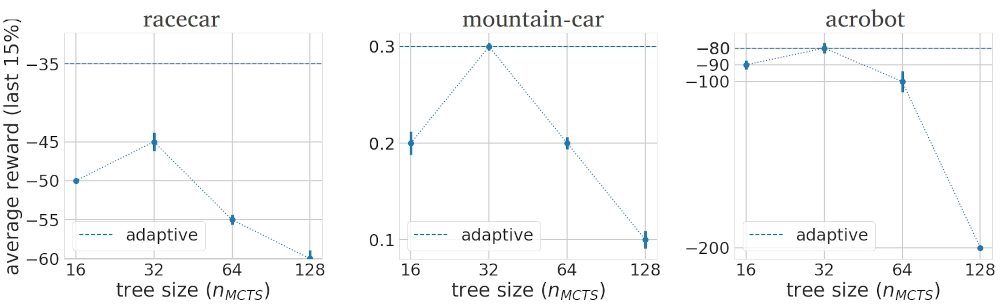
Instead of performing a fixed number of n MCTS iterations at each decision step, adaptively changing N_MCTS
based on the uncertainty of the current state’s value estimate could increase computational efficiency and performance.
N_MCTS can be defined at each decision step by comparing the root return variance to a rolling baseline estimate.
If the estimates are relatively uncertain, additional iterations are carried out.
Visualization of additional iterations during the learning process in case of escaping valley in the mountain-car environment.

BSc in Mechatronics Engineering•Budapest• 2015
• applied mechanics profile
• core modules in fluid mechanics, multibody dynamics, solid mechanics, vibrations, electrodynamics, sensor technology
• thesis project: The application of generalized hold functions in delayed digital control systems (supervisor: Tamas Insperger)
• Access thesis
• Digital control • Stability analysis • Matlab • Mathematica
Generalized hold function in delayed digital control systems
The thesis examines system stability in case of different hold functions applied in
digital control, with and without considering time delays within the control system.
The stability analysis was carried out for the classical control problem of balancing an inverted
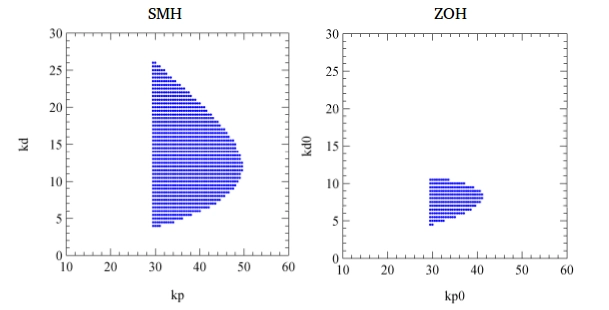
pendulum with a discrete time PD controller. The stability analysis of the pendulum system was carried out in case of the zero-order, first-order, second-order and system-matched hold (SMH) functions.
The system-matched hold is a special form of the generalized sampled data hold function, where the hold function is determined from system dynamics.
The stability was presented in the form of stability charts, which were constructed in the plane of the proportional and
derivative control gain parameters. The stability analysis showed that the application of
higher order hold functions can increase the size of the stable region in the gain
parameters plane. The hold function for SMH was also constructed and it was shown that the stable region becomes infinite when there is no time delay assumed in the system. It
was also shown that in all cases, the presence of time delays in the system significantly decreases
the stable region. The critical pendulum length for a given time delay is the smallest pendulum length that can be stabilized. The
critical length was calculated in case of the ZOH hold, then it was demonstrated that with
the application of higher order hold functions the critical minimal length of the pendulum
for the given time delay can be decreased.
thesis supervisor:Tamas Insperger
Software Engineer• 2019 - 2020
• worked in autonomous tram project in cooperation with Siemens AG Berlin
• tasks in software evaluation (parallelization of ADAS pipeline, implementing automatic map update) - Python, Docker, Jenkins
• tasks in computer vision component (software development) - C++, ROS
• agile development
Research Intern•Tubigen• February 2017 - July 2017
• project in depth-camera based pole balancing on humanoid robot platform
• integrated Bayesian vision-based tracking system with LQR control for pole balancing - C++, ROS
• implemented deep neural network for angle regression based on ROS depth images - Python, Tensorflow
• experience with real-time robot system, motion capture system, depth cameras
• literature research on learning algorithms in vision based control
Research Intern•Budapest• June 2014 - August 2014
• compared Lattice-Boltzmann method with traditional CFD methods for fluid dynamics simulations (C++)
• literature review on Lattice-Boltzmann method for reactive flow simulations
Summer School•Virtual• August 2021
• two-week summer school in deep learning and machine learning
Deep Learning track•Virtual• August 2021
• three-week course on the theory and techniques of deep learning with an emphasis on neuroscience
• course project comparing recurrent neural networks for human motor decoding from neural signals
Summer School•Politehnica University of Bucharest• July 2019
• one-week summer school around topics in deep learning and reinforcement learning organized by AI researchers
• best poster award
Summer School• ETH Zurich• July 2017
• participated in lectures and practicals on topics in areas of deep
learning, learning theory, robotics and control and computer vision
ATHENS Programme• KU Leuven• November 2014
• intensive programming course, focus on generic programming
dataset collection
🛠 • Multimodal Communication • Project Aria Glasses • Gaze Tracking • Egocentric Video • Object References
KTH-ARIA Referential captures multimodal referential communication
in a controlled kitchen-lab environment using Meta Project Aria smart glasses
(egocentric RGB + gaze tracking), GoPro third-person videos, and additional sensors.
• 25 participants, 125 sessions, ~396k frames (3.67h at 30fps).
• Includes synchronized gaze, speech, object references, and segmentation masks.
• Designed for research in multimodal AI, spatial reasoning, and
gesture generation.
The dataset is publicly available on Hugging Face:
dataset link
.
master thesis work
• Planning • Monte Carlo tree search • Deep learning • Python• Tensorflow
Generalization and locality in the AlphaZero algorithm
The AlphaGo was first to achieve professional human level performance in the game of Go. It combined pattern knowledge through the use of a deep neural network and search using Monte Carlo tree search (MCTS).
MCTS uses local and dynamic position evaluation in contrast to traditional search methods, where static evaluation functions store knowledge about all positions.
It has been suggested that the locality of information is the main strength of the MCTS algorithm. As each edge stores its own statistics, it is easier to locally separate the effect of actions.
On the other hand, the main strength of deep neural networks is their generalization capacity, which allows them to utilize information from previous experience to new situations.
It can be argued that the success of AlphaGo can be explained by the complementary strengths of MCTS and deep neural networks.
The thesis examines the relative importance of local search and generalization in the AlphaZero algorithm in single-player, deterministic and fully-observable reinforcement learning environments (OpenAI, Pybullet gym environments).
The localization versus generalization question was examined through varying the number of MCTS iteration steps N_MCTS, while keeping other hyperparameters of the algorithm fixed.
The N_MCTS parameter corresponds to the number of simulated trajectories performed using the environment emulator before each action selection step in the real environment.
Under a fixed time budget the number of MCTS iterations defines how much effort is spent on acquiring more accurate values through building large search trees at each decision step versus improving generalization by updating the network more frequently.
Instead of performing a fixed number of n MCT S iterations at each decision step, adaptively changing N_MCTS
based on the uncertainty of the current state’s value estimate could increase computational efficiency and performance.
N_MCTS can be defined at each decision step by comparing the root return variance to a rolling baseline estimate.
If the estimates are relatively uncertain, additional iterations are carried out.
Visualization of additional iterations during the learning process in case of escaping valley in the mountain-car environment.
side project
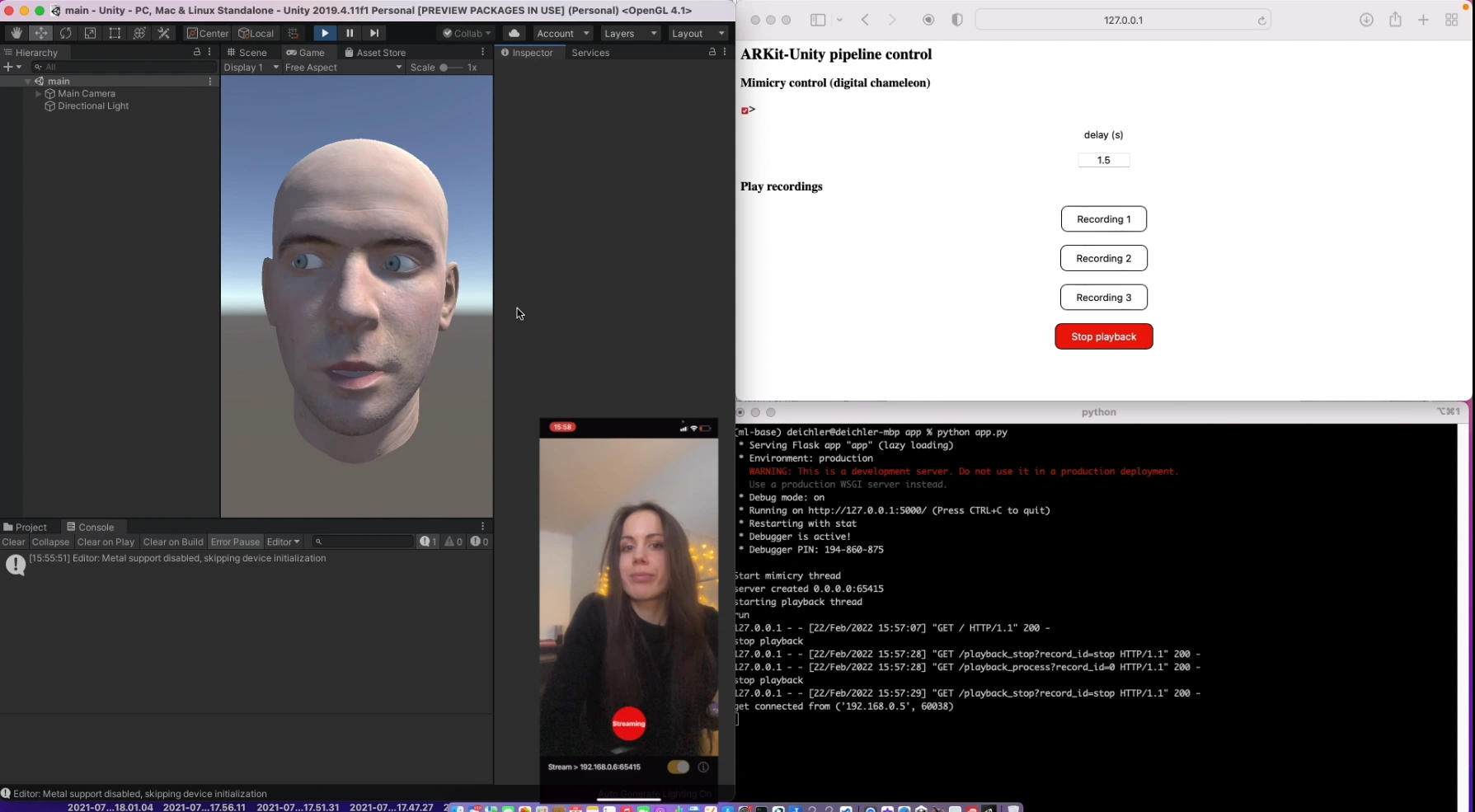
🛠 • Multimodal Learning • Unity WebGL • Flask Backend • Diffusion Models
Development of an Interactive Gesture Visualization Tool
This project focuses on visualizing semantically coherent co-speech gestures generated by the Contrastive Speech and Motion Pretraining (CSMP) system. The CSMP visualization tool is hosted on Hugging Face Spaces, a platform enabling interactive model demonstrations. Users can experiment with CSMP's capabilities, including querying precomputed motion-audio clips or synthesizing new gestures based on text prompts. Hugging Face Spaces simplifies accessibility and interaction, allowing researchers and practitioners to evaluate the system's performance in real time.
Hugging Face Spaces.
The online synthesis pipeline involves:
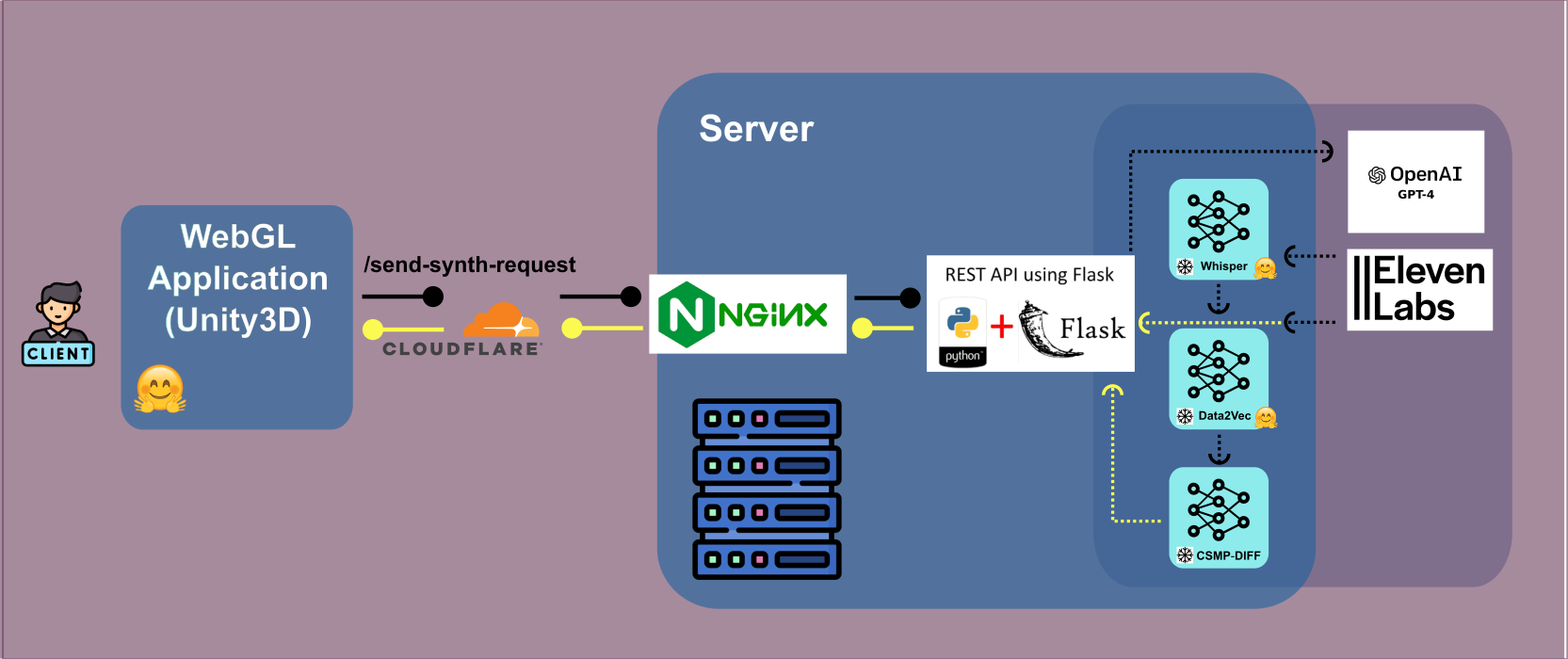
The tool's client-server architecture combines a Unity WebGL frontend with a Flask backend to handle queries, synthesis, and real-time updates. It enables dynamic gesture rendering and supports seamless interactivity for researchers and developers. The project has demonstrated high naturalness and speech appropriateness, validated through the GENEA Challenge evaluations.
Useful links:














